Chapter 14 Causal inference 2: Model-based estimation of causal estimands
Sources of inspiration: Luque Fernandez, M.A. et al.
(2018) Stat Med
2018;37(16):2530-2546 and
Smith et al. (2022) Stat Med
2022;41(2):407-432.
14.1 Introduction
We shall illustrate with simulated data the estimation of causal effects of a binary exposure \(X\) when the outcome \(Y\) is also binary, and there is a set of four covariates \(Z = (Z_1, Z_2, Z_3, Z_4)\). As a background story, we imagine a population of cancer patients, in whom the variables and the assumed marginal distributions of the covariates are
| Variable | Description |
|---|---|
| \(X\) | treatment; 1: radiotherapy only, 0: radiotherapy + chemotherapy |
| \(Y\) | death during one year after diagnosis of cancer |
| \(Z_1\) | sex; 0: man, 1: woman; \(Z_1 \sim \text{Bern}(0.5)\) |
| \(Z_2\) | age group 0; young, 1: old; \(Z_2 \sim \text{Bern}(0.65)\) |
| \(Z_3\) | stage of cancer; 4 classes; \(Z_3 \sim \text{DiscUnif}(1, \dots, 4)\) |
| \(Z_4\) | comorbidity score; 5 classes; \(Z_3 \sim \text{DiscUnif}(1, \dots, 5)\) |
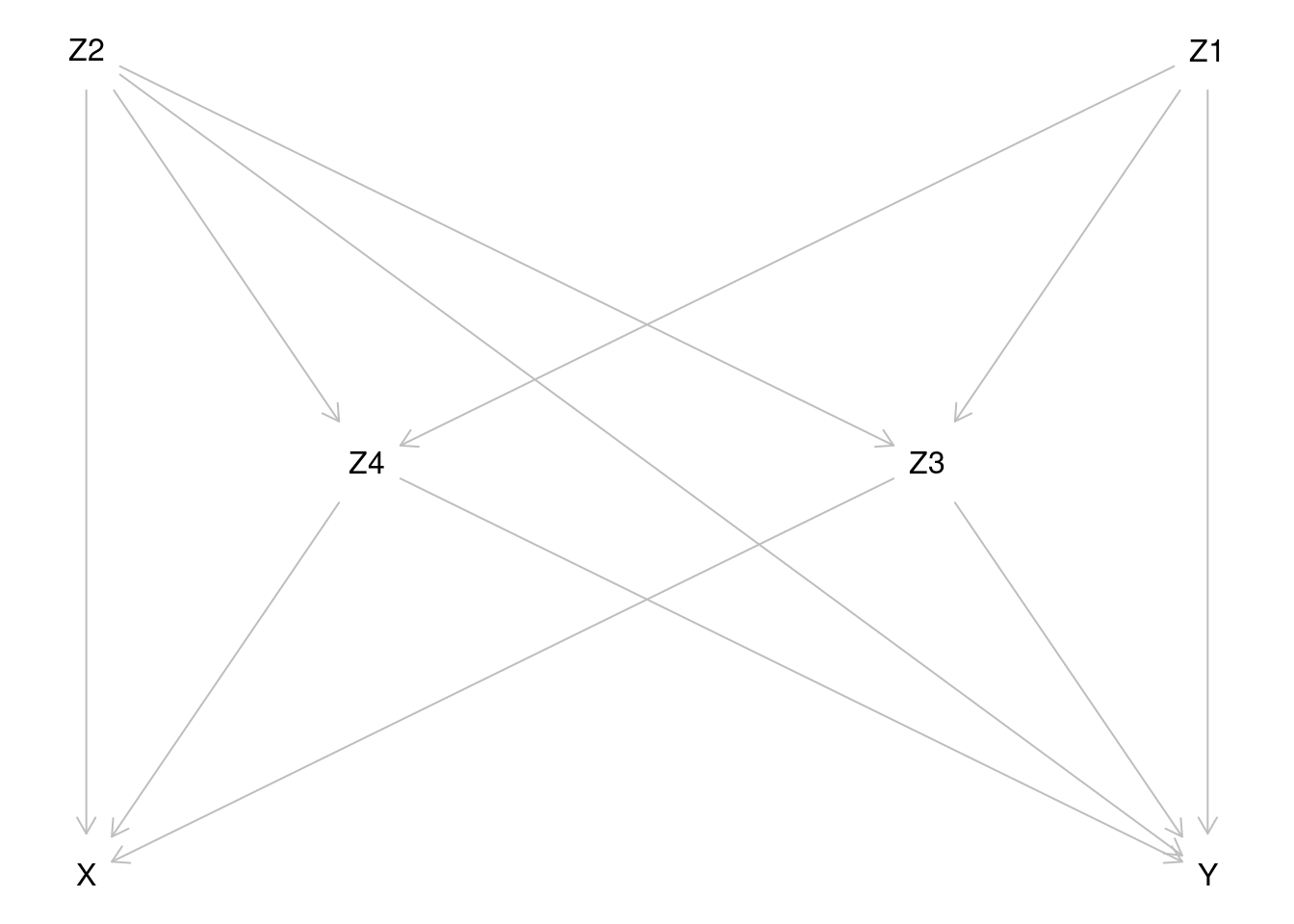
For simplicity, covariates \(Z_3\) and \(Z_4\) are treated as continuous
variables in the models. The assumed causal diagram
is drawn using dagitty and is shown below.
For more generic notation, the probabilities of \(Y=1\) will be expressed as expectations, e.g. \[E(Y^{X=x}) = P(Y^{X=x}=1) \quad \text{and} \quad E(Y|X=x, Z=z) = P(Y=1|X=x, Z=z), \] where \(Z\) is the vector of relevant covariates.
The same principle is applied in expressing the conditional
probability of \(X=1\), i.e. being exposed, given \(Z=z\):
\[ E(X|Z=z) = P(X=1|Z=z). \]
The fitted or predicted probabilities
of \(Y=1\) are denoted as fitted \(\widehat{Y}\) or predicted values
\(\widetilde{Y}\) of \(Y\) with pertinent subscripts and/or superscripts.
– Both \(X\) and \(Y\) are modelled by logistic regression. The expit-function
or inverse of the logit function is defined:
\(\text{expit}(u) = 1/(1 + e^{-u})\), \(u\in R\). This is equal to the
cumulative distribution function of the standard logistic distribution,
the values of which are returned in R by plogis(u). The R function
that returns values of the logit-function is qlogis().
The true model assumed for the dependence of exposure \(X\) on covariates: \[ E(X|Z_1 = z_1, \dots, Z_4 = z_4) = \text{expit}(-5 + 0.05z_2 + 0.25z_3 + 0.5z_4 + 0.4z_2z_4) . \] The assumed true model for the outcome is \[ E(Y|X=x, Z_1 = z_1, \dots, Z_4 = z_4) = \text{expit}(-1 + x - 0.1z_1 + 0.35z_2 + 0.25z_3 + 0.20z_4 + 0.15z_2z_4) \] Note that \(X\) does not depend on \(Z_1\), and that in both models there is a product term \(Z_2 Z_4\), the effect of which appears weaker for the outcome model.
14.2 Control of confounding
Based on inspection of the causal diagram, can you provide justification for the claim that variables \(Z_2, Z_3\) and \(Z_4\) form a proper subset of the four covariates, which is sufficient to block all backdoor paths between \(X\) and \(Y\) and thus remove confounding?
Even though we have such a minimal sufficient set as indicated in item (a), why it still might be useful to include covariate \(Z_1\), too, when modelling the outcome?
14.3 Generation of target population and true models
- Load the necessary packages.
- Define two R-functions, which compute the expected values for the exposure and those for the outcome based on the assumed true exposure model and the true outcome model, respectively.
EX <- function(z2, z3, z4) {
plogis(-5 + 0.05 * z2 + 0.25 * z3 + 0.5 * z4 + 0.4 * z2 * z4)
}
EY <- function(x, z1, z2, z3, z4) {
plogis(-1 + x - 0.1 * z1 + 0.35 * z2 + 0.25 * z3 +
0.20 * z4 + 0.15 * z2 * z4)
}- Define the function for the generation of data by simulating random values from pertinent probability distributions based on the given assumptions.
genData <- function(N) {
z1 <- rbinom(N, size = 1, prob = 0.5) # Bern(0.5)
z2 <- rbinom(N, size = 1, prob = 0.65) # Bern(0.65)
z3 <- trunc(runif(N, min = 1, max = 5), digits = 0) # DiscUnif(1,4)
z4 <- trunc(runif(N, min = 1, max = 6), digits = 0) # DiscUnif(1,5)
x <- rbinom(N, size = 1, prob = EX(z2, z3, z4))
y <- rbinom(N, size = 1, prob = EY(x, z1, z2, z3, z4))
data.frame(z1, z2, z3, z4, x, y)
}- Generate a data frame
ddfor a big target population of 500000 subjects
14.4 Factual and counterfactual risks - associational and causal contrasts
- Compute the factual risks of death for the two exposure groups \[ E(Y|X=x) = P(Y=1|X=x) = \frac{P(Y=1\ \&\ X=x)}{P(X=x)}, \quad x=0,1, \] in the whole target population, as well as their associational contrasts: risk difference, risk ratio, and odds ratio. Before that define a useful function
Contr <- function(mu1, mu0) {
RD <- mu1 - mu0
RR <- mu1 / mu0
OR <- (mu1 / (1 - mu1)) / (mu0 / (1 - mu0))
return(c(mu1, mu0, RD = RD, RR = RR, OR = OR))
}
Ey1fact <- with(dd, sum(y == 1 & x == 1) / sum(x == 1))
Ey0fact <- with(dd, sum(y == 1 & x == 0) / sum(x == 0))
round(Contr(Ey1fact, Ey0fact), 4)## RD RR OR
## 0.8949 0.6288 0.2661 1.4232 5.0286How much bigger is the risk of death of those factually exposed to radiotherapy only as compared with those receiving chemotherapy, too?
- Compute now the true counterfactual or potential risks of death \[ E(Y_i^{X_i=x}) = P(Y_i^{X_i=x}=1) = \pi_i^{X_i=x} \] for each individual under the alternative treatments or exposure values \(x=0,1\) with given covariate values, then the average or overall counterfactual risks \(E(Y^{X=1}) = \pi^1\) and \(E(Y^{X=0}) = \pi^0\) in the population, and finally the true marginal causal contrasts for the effect of \(X\): \[ \begin{aligned} \text{RD} & = E(Y^{X=1})-E(Y^{X=0}), \qquad \text{RR} = E(Y^{X=1})/E(Y^{X=0}), \\ \text{OR} & = \frac{E(Y^{X=1})/[1 - E(Y^{X=1})]}{E(Y^{X=0})/[1 - E(Y^{X=0})] } \end{aligned} \]
dd <- transform(dd,
EY1.ind = EY(x = 1, z1, z2, z3, z4),
EY0.ind = EY(x = 0, z1, z2, z3, z4)
)
EY1pot <- mean(dd$EY1.ind)
EY0pot <- mean(dd$EY0.ind)
round(Contr(EY1pot, EY0pot), 4)## RD RR OR
## 0.8273 0.6530 0.1743 1.2670 2.5462- Compare the associational contrasts computed in item 4.1 with the causal contrasts in item 4.2. What do you conclude about confoundedness of the associational contrasts?
14.5 Outcome modelling and estimation of causal contrasts by g-formula
As the first approach for estimating causal contrasts of interest we apply the method of standardization or g-formula. It is based on a hopefully realistic enough model for \(E(Y|X=x, Z=z)\), i.e. how the risk of outcome is expected to depend on the exposure variable \(X\) and on a sufficient set \(Z\) of confounders. The potential or counterfactual risks \(E(Y^{X=x}), x=0,1\), are marginal expectations of the above quantities, standardized over the joint distribution of the confounders \(Z\) in the target population. \[ E(Y^{X=x}) = E_Z[E(Y|X=x,Z)] = \int E(Y|X=x, Z=z)dF_Z(z), \quad x=0,1. \]
- Assume now a slightly misspecified model
mYfor the outcome, which contains only main effect terms of the explanatory variables: \[ \pi_i = E(Y_i|X_i=x_i, Z_{i1}=z_{i1}, \dots, Z_{i4}=z_{i4}) = \text{expit}\left(\beta_0 + \delta x_i + \sum_{j=1}^4 \beta_j z_{ij} \right) \] Fit this model on the target population using functionglm()
mY <- glm(y ~ x + z1 + z2 + z3 + z4, family = binomial, data = dd)
round(ci.lin(mY, Exp = TRUE)[, c(1, 5)], 3)## Estimate exp(Est.)
## (Intercept) -1.240 0.289
## x 1.052 2.863
## z1 -0.095 0.909
## z2 0.767 2.153
## z3 0.250 1.284
## z4 0.279 1.322There is not much idea in looking at the standard errors or confidence intervals in such a big population.
- For each subject \(i\), compute the fitted individual risk \(\widehat{Y_i}\) as well as the predicted potential (counterfactual) risks \(\widetilde{Y_i}^{X_i=x}\) for both exposure levels \(x=0,1\) separately, keeping the individual values of the \(Z\)-variables as they are.
dd$yh <- predict(mY, type = "response") # fitted values
dd$yp1 <- predict(mY, newdata = data.frame(
x = rep(1, N), # x=1
dd[, c("z1", "z2", "z3", "z4")]
), type = "response")
dd$yp0 <- predict(mY, newdata = data.frame(
x = rep(0, N), # x=0
dd[, c("z1", "z2", "z3", "z4")]
), type = "response")- Applying the method of standardization or
g-formula compute now the
point estimates
\[ \widehat{E}_g(Y^{X=x}) =
\frac{1}{n} \sum_{i=1}^n \widetilde{Y}_i^{X_i=x}, \quad x=0,1. \]
of the two counterfactual risks \(E(Y^{X=1}) = \pi^1\) and
\(E(Y^{X=0})=\pi^0\) as well as
those of the marginal causal contrasts
## RD RR OR
## 0.8330 0.6508 0.1822 1.2800 2.6763The marginal expectations \(E_Z[E(X=x, Z)]\) taken over the joint distribution of the confounders \(Z\) are empirically estimated from the actual data representing the target population by simply computing the arithmetic means of the individually predicted values \(\widetilde{Y_i}^{X_i=x}\) of the outcome for the two exposure levels.
Compare the estimated contrasts with the true ones in item 4.2 above. How big is the bias due to slight misspecification of the outcome model? Compare in particular the estimate of the marginal OR here with the conditional OR obtained in item 5.1 from the pertinent coefficient in the logistic model. Which one is closer to 1?
- Perform the same calculations using the tools
in package
stdReg(see Sjölander 2016)
##
## Formula: y ~ x + z1 + z2 + z3 + z4
## Family: binomial
## Link function: logit
## Exposure: x
##
## Estimate Std. Error lower 0.95 upper 0.95
## 0 0.651 0.000733 0.649 0.652
## 1 0.833 0.001562 0.830 0.836## Estimate Std. Error lower 0.95 upper 0.95
## 0 0.0000 0.0000 0.0000 0.0000
## 1 0.1822 0.0017 0.1788 0.1856## Estimate Std. Error lower 0.95 upper 0.95
## 0 1.00 0.0000 1.0000 1.0000
## 1 1.28 0.0028 1.2745 1.2855## Estimate Std. Error lower 0.95 upper 0.95
## 0 1.0000 0.0000 1.0000 1.0000
## 1 2.6763 0.0315 2.6146 2.7379Check that you got the same point estimates as
in the previous item.
Again, the confidence intervals are not very
meaningful when analysing
the data covering the whole big target population.
Of course, when
applied to real sample data they are relevant.
In stdReg package, the
standard errors are obtained by the multivariate
delta method built upon
M-estimation and robust sandwich estimator of the
pertinent covariance
matrix, and approximate confidence intervals are derived
from these in the usual way.
14.6 Inverse probability weighting (IPW) by propensity scores
The next method is based on weighting each individual observation by the inverse of the probability of belonging to that particular exposure group, which was realized, this probability being predicted by the determinants of exposure.
- Fit first a somewhat misspecified model for the exposure including the main effects of the \(Z\)-variables only. \[ p_i = E(X_i| Z_{1i} = z_{1i}, \dots, Z_{4i} = z_{4i}) = \text{expit}(\gamma_0 + \gamma_1 z_{1i} + \gamma_2 z_{2i} + \gamma_3 z_{i3} + \gamma_4 z_{4i} ), \quad i=1, \dots N \]
mX <- glm(x ~ z1 + z2 + z3 + z4,
family = binomial(link = logit), data = dd
)
round(ci.lin(mX, Exp = TRUE)[, c(1, 5)], 4)## Estimate exp(Est.)
## (Intercept) -6.3031 0.0018
## z1 -0.0161 0.9840
## z2 1.6260 5.0833
## z3 0.2391 1.2702
## z4 0.8369 2.3093- Extract the propensity scores, i.e. fitted probabilities of belonging to exposure group 1: \(\text{PS}_i = \widehat{p_i}\), and compare their distribution between the two groups.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.005256 0.041532 0.112765 0.172440 0.248554 0.613993with(subset(dd, x == 0), plot(density(PS), lty = 2))
with(subset(dd, x == 1), lines(density(PS), lty = 1))How different are the distributions? Are they sufficiently overlapping?
- Compute the weights \[ \begin{aligned} W_i & = \frac{1}{\text{PS}_i}, \quad \text{when }\ X_i=1, \\ W_i & = \frac{1}{1-\text{PS}_i}, \quad \text{when }\ X_i=0 . \end{aligned} \] Look at the sum as well as the distribution summary of the weights in the exposure groups. The sum of weights should be close to \(N\) in both groups.
## 0 1
## 498880.5 565237.5- Compute now the weighted estimates of the potential or counterfactual risks for both exposure categories \[ \widehat{E}_w(Y^{X = x}) = \frac{ \sum_{i=1}^n {\mathbf 1}_{ \{X_i=x\} } W_i Y_i } {\sum_{i=1}^n {\mathbf 1}_{ \{X_i=x\} }W_i} = \frac{ \sum_{X_i = x} W_i Y_i }{\sum_{X_i=x} W_i}, \quad x = 0,1, \] and their causal contrasts, for instance \[ \widehat{\text{RD}}_{w} = \widehat{E}_w(Y^{X = 1}) - \widehat{E}_w(Y^{X = 0}) = \frac{ \sum_{i=1}^n X_i W_i Y_i }{\sum_{i=1}^n X_i W_i} - \frac{ \sum_{i=1}^n (1-X_i) W_i Y_i }{\sum_{i=1}^n (1-X_i) W_i} \]
EY1pot.w <- sum(dd$x * dd$w * dd$y) / sum(dd$x * dd$w)
EY0pot.w <- sum((1 - dd$x) * dd$w * dd$y) / sum((1 - dd$x) * dd$w)
round(Contr(EY1pot.w, EY0pot.w), 4)## RD RR OR
## 0.8037 0.6519 0.1518 1.2329 2.1868These estimates seem to be somewhat downward biased when comparing to true values. Could this be because of omitting the relatively strong product term effect of \(Z_2\) and \(Z_4\)?
14.7 Improving IPW estimation and using R package PSweight
We now try to improve IPW-estimation by a richer exposure
model. In
computations we shall utilize the R package
PSweight (see PSweight
vignette).
- First, we compute the propensity scores
and weights from a more flexible exposure model,
which contains all pairwise product terms
of the parents of \(X\).
According to the causal diagram, \(Z_1\) is
not in that subset, so it
is left out. The exposure model is
specified and the weights are
obtained as follows using function
SumStat()inPSweight:
mX2 <- glm(x ~ (z2 + z3 + z4)^2, family = binomial, data = dd)
round(ci.lin(mX2, Exp = TRUE)[, c(1, 5)], 3)## Estimate exp(Est.)
## (Intercept) -5.085 0.006
## z2 0.143 1.154
## z3 0.243 1.275
## z4 0.527 1.693
## z2:z3 -0.003 0.997
## z2:z4 0.376 1.456
## z3:z4 0.001 1.001psw2 <- SumStat(
ps.formula = mX2$formula, data = dd,
weight = c("IPW", "treated", "overlap")
)
dd$PS2 <- psw2$propensity[, 2]
dd$w2 <- ifelse(dd$x == 1, 1 / dd$PS2, 1 / (1 - dd$PS2))
plot(density(dd$PS2[dd$x == 0]), lty = 2)
lines(density(dd$PS2[dd$x == 1]), lty = 1)Note that apart from ordinary IPW, other types of weights can also also obtained. These are relevant when estimating other kinds of causal contrasts, like “average treatment effect among the treated” (ATT, see below) and “average treatment effect in the overlap (or equipoise) population” (ATO).
PSweightincludes some useful tools to examine the properties of the distribution and to check the balance of the propensity scores, for instance
It is desirable that the horisontal values of these measures for given weights are less than 0.1.
- Estimation and reporting of the causal contrasts. For relative contrasts, the summary method provides the results on the log-scale; therefore \(\exp\)-transformation
## Original group value: 0, 1
##
## Point estimate:
## 0.6526, 0.8255##
## Closed-form inference:
##
## Original group value: 0, 1
##
## Contrast:
## 0 1
## Contrast 1 -1 1
##
## Estimate Std.Error lwr upr Pr(>|z|)
## Contrast 1 0.1729179 0.0025636 0.1678934 0.17794 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1##
## Closed-form inference:
##
## Inference in log scale:
## Original group value: 0, 1
##
## Contrast:
## 0 1
## Contrast 1 -1 1
##
## Estimate Std.Error lwr upr Pr(>|z|)
## Contrast 1 0.2350512 0.0031789 0.2288207 0.24128 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## [1] 1.265 1.257 1.273## [1] 2.519 2.434 2.606Compare these with the previous IPW estimate as well as the true values. Have we obtained nearly unbiased results?
The standard errors provided by PSweight
are by default based on the
empirical sandwich covariance matrix and application
of delta method as
appropriate. Bootstrapping is also possible but is
computationally very
intensive and is recommended to be used only in relatively small
samples.
14.8 Effect of exposure among those exposed
If we are interested in the causal contrasts describing the effect of exposure among those exposed (like ATE), the relevant factual and counterfactual risks in that subset are
\[ \begin{aligned} \pi^1_1 & = E(Y^{X=1}|X=1) = E(Y|X=1) = \pi_1, \\ \pi^0_1 & = E(Y^{X=0}|X=1) = \sum_{X_i=1} E(Y|X=0, Z=z)P(Z=z|X=1) \end{aligned} \]
We are thus making and “observed vs. expected” comparison, in which the \(z\)-specific risks in the unexposed are weighted by the distribution of \(Z\) in the exposed subset of the target population. The risks and their contrasts are estimated from the fit of the outcome model:
EY1att.g <- mean(subset(dd, x == 1)$yp1)
EY0att.g <- mean(subset(dd, x == 1)$yp0)
round(Contr(EY1att.g, EY0att.g), 4)## RD RR OR
## 0.8949 0.7560 0.1389 1.1837 2.7488Compare the results here with those for the whole target population. What do you observe?
Have you any guess about the causal effect of exposure among the unexposed; is it bigger or smaller than among the exposed or among the whole population?
Incidentally, the true causal contrasts among the exposed based on the true model are similarly obtained from the quantities in item 4.2 above:
EY1att <- mean(subset(dd, x == 1)$EY1.ind)
EY0att <- mean(subset(dd, x == 1)$EY0.ind)
round(Contr(EY1att, EY0att), 4)## RD RR OR
## 0.8955 0.7680 0.1275 1.1661 2.5896Compare the estimates in the previous item with the true values obtained here.
- When wishing to estimate
the effect of exposure among the exposed using the IPW
approach, then the weights are \(W_i = 1\) for the exposed and
\(W_i = \text{PS}_i/(1-\text{PS}_i)\) for the unexposed.
Call again
PSweightbut with another choice of weight:
## Original group value: 0, 1
## Treatment group value: 1
##
## Point estimate:
## 0.7667, 0.8949## [1] 0.1282## [1] 1.167## [1] 2.592Compare the results here with those obtained by g-formula in item 8.1 and with the true contrasts above.
14.9 Double robust estimation by augmented IPW
Let us attempt to correct the estimates by a double robust (DR) approach called augmented IPW estimation (AIPW), which combines the g-formula and the IPW approach. The classical AIPW-estimator can be expressed in two ways: either an IPW-corrected g-formula estimator, or a g-corrected IPW-estimator.
\[ \begin{aligned} \widehat{E}_a(Y^{X=x}) & = \widehat{E}_g(Y^{X=x}) + \frac{1}{n} \sum_{i=1}^n {\mathbf 1}_{\{X_i=x\}} W_i ( Y_i - \widetilde{Y}_i^{X_i=x} ) \\ & = \widehat{E}_w(Y^{X=x}) + \frac{1}{n} \sum_{i=1}^n ( 1 - {\mathbf 1}_{\{X_i=x\}} W_i ) \widetilde{Y}_i^{X_i=x}. \end{aligned} \]
- We shall first combine the results from the slightly misspecified outcome model with those from the more misspecified exposure model.
EY1pot.a <- EY1pot.g + mean( 1*(dd$x==1) * dd$w * (dd$y - dd$yp1) )
EY0pot.a <- EY0pot.g + mean( 1*(dd$x==0) * dd$w * (dd$y - dd$yp0) )
round(Contr(EY1pot.a, EY0pot.a), 4)## RD RR OR
## 0.8241 0.6523 0.1718 1.2634 2.4972Compare these results with those obtained by g-formula and by non-augmented IPW method. Was augmentation successful?
- Let us then look, how close we get when combining the results from the slightly misspecified outcome model with the correct exposure model using the alternative AIPW-formula
EY1pot.w2 <- ipw2est$muhat[2]
EY0pot.w2 <- ipw2est$muhat[1]
EY1pot.a2 <- EY1pot.w2 + mean( (1 - 1*(dd$x==1) * dd$w2) * dd$yp1 )
EY0pot.a2 <- EY0pot.w2 + mean( (1 - 1*(dd$x==0) * dd$w2) * dd$yp0 )
round(Contr(EY1pot.a2, EY0pot.a2), 4)## 1 0 RD.1 RR.1 OR.1
## 0.8261 0.6526 0.1735 1.2658 2.5285Compare the results with previous ones. How successful was augmentation now?
AIPW-estimates and confidence
intervals for the causal contrasts of interest can
be obtained, for instance, using PSweight by adding
the model formula of the outcome model
as the value for the argument out.formula.
14.10 Double robust, targeted maximum likelihood estimation (TMLE)
We now consider now another double robust approach, known as targeted maximum likelihood estimation (TMLE). It also corrects the estimator obtained from the outcome model by elements that are derived from the exposure model. The corrections are, though, not as intuitive as those in AIPW. See Schuler and Rose (2017) for more details.
- The first step is to utilize the propensity scores obtained above for the correct exposure model and define the “clever covariates”
- Then, a working model is fitted for the outcome,
in which the clever
covariates are explanatory variables, but the model
also includes
the previously fitted linear predictor
\(\widehat{\eta}_i = \text{logit}(\widehat Y_i)\)
from the original
outcome model
mYas an offset term; see item 5.2. Moreover, the intercept is removed.
epsmod <- glm(y ~ -1 + H0 + H1 + offset(qlogis(yh)),
family = binomial(link = logit), data = dd
)
eps <- coef(epsmod)
eps## H0 H1
## 0.007197951 -0.002859654- The logit-transformed predicted values \(\widetilde{Y}_i^{X_i=1}\) and \(\widetilde{Y}_i^{X_i=0}\) of the potential or counterfactual individual risks from the original outcome model are now corrected by the estimated coefficients of the clever covariates, and the corrected predictions are returned to the original scale.
ypred0.H <- plogis(qlogis(dd$yp0) + eps[1] / (1 - dd$PS2))
ypred1.H <- plogis(qlogis(dd$yp1) + eps[2] / dd$PS2)- Estimates of the causal contrasts:
## RD RR OR
## 0.8246 0.6526 0.1720 1.2635 2.5020Compare these with previous results and with the true values.
14.11 Double robust estimation with AIPW and tmle packages
It may be difficult to specify conventional generalized linear models or even generalized additive models for exposure and outcome which are sufficiently realistic, yet which do not suffer from overfitting. Modern approaches of statistical learning, aka “machine learning” provide tools for flexible modelling, which may be used to reduce the risk of misspecification, if thoughtfully applied.
There are a few R packages in which some general
algorithmic approaches for supervised learning
are implemented for estimating causal parameters.
For instance, package AIPW
(see Zhong et al., 2021)
utilizes
several learning algorithms for exposure and outcome modelling
and then performs AIPW estimation of the
parameters of interest coupled with
calculation of confidence intervals. Package tmle
(see Karim and Frank, 2021)
performs same tasks but uses the TMLE approach
in estimation.
Both AIPW and tmle lean on the
SuperLearner package, which uses multiple learning
algorithms (e.g. GLM, GAM, Random Forest, Recursive Partitioning,
Gradient Boosting, etc.) for constructing
predictions of the counterfactual quantities, and
then creates an optimal weighted average of those models,
aka an “ensemble”. These algorithms are computationally
highly intensive. Fitting models with only 3 or 4
covariates as in this practical
on our target cohort of 500,000 subjects
would take hours on an ordinary laptop. With a study population
of 5000 it takes several minutes.